This is a sequel to The Tensor Product in response to a comment posted there. It endeavours to explain the difference between a tensor and a matrix. It also explains why ‘tensors’ were not mentioned in The Tensor Product.
A matrix is a two-dimensional array of numbers (belonging to a field such as 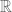 or
or 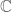 ) which can be used freely for any purpose, including for organising data collected from an experiment. Nevertheless, there are a number of commonly defined operations involving scalars, vectors and matrices, such as matrix addition, matrix multiplication, matrix-by-vector multiplication and scalar multiplication. These operations allow a matrix to be used to represent a linear map from one vector space to another, and it is this aspect of matrices that is the most relevant here.
) which can be used freely for any purpose, including for organising data collected from an experiment. Nevertheless, there are a number of commonly defined operations involving scalars, vectors and matrices, such as matrix addition, matrix multiplication, matrix-by-vector multiplication and scalar multiplication. These operations allow a matrix to be used to represent a linear map from one vector space to another, and it is this aspect of matrices that is the most relevant here.
Although standard usage means that an 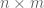 matrix over defines a linear map from the vector space
matrix over defines a linear map from the vector space 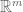 to the vector space
to the vector space 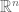 , this is an artefact of and implicitly being endowed with a canonical choice of basis vectors. It is perhaps cleaner to start from scratch and observe that a matrix on its own does not define a linear map between two vector spaces: given two two-dimensional vector spaces
, this is an artefact of and implicitly being endowed with a canonical choice of basis vectors. It is perhaps cleaner to start from scratch and observe that a matrix on its own does not define a linear map between two vector spaces: given two two-dimensional vector spaces  and the matrix
and the matrix ![A = [1,2;3,4]](https://s0.wp.com/latex.php?latex=A+%3D+%5B1%2C2%3B3%2C4%5D&bg=ffffff&fg=555555&s=0&c=20201002) (by which I mean the two-by-two matrix whose elements are, from left-to-right top-to-bottom,
(by which I mean the two-by-two matrix whose elements are, from left-to-right top-to-bottom,  ), what linear map from
), what linear map from 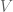 to
to 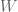 does
does  represent? By convention, a linear map is represented by a matrix in the following way, with respect to a particular choice of basis vectors for and for . Let
represent? By convention, a linear map is represented by a matrix in the following way, with respect to a particular choice of basis vectors for and for . Let 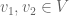 be a basis for , and
be a basis for , and 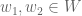 a basis for . If
a basis for . If 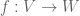 is a linear map then it is fully determined once the values of
is a linear map then it is fully determined once the values of 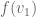 and
and  are revealed. Furthermore, since is an element of , it can be written as
are revealed. Furthermore, since is an element of , it can be written as 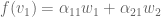 for a unique choice of scalars
for a unique choice of scalars 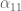 and
and  . Similarly,
. Similarly, 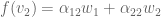 . Knowing the scalars
. Knowing the scalars  and
and  , together with knowing the choice of basis vectors
, together with knowing the choice of basis vectors 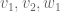 and
and  , allows one to determine what the linear map
, allows one to determine what the linear map 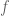 is. (An alternative but essentially equivalent approach would have been to agree that a matrix defines a linear map from to , and therefore, to represent a linear map by a matrix, it is first necessary to choose an isomorphism from to and an isomorphism from to .)
is. (An alternative but essentially equivalent approach would have been to agree that a matrix defines a linear map from to , and therefore, to represent a linear map by a matrix, it is first necessary to choose an isomorphism from to and an isomorphism from to .)
Unlike a matrix, which can only represent a linear map between vector spaces once a choice of basis vectors has been made, a tensor is a linear (or multi-linear) map. The generalisation from linear to multi-linear maps is a distraction which may lead one to believe the difference between a tensor and a matrix is that a tensor is a generalisation of a matrix to higher dimensions, but this is missing the key point: the machinery of changes of coordinates, which is external to the definition of a matrix as an array of numbers, is internal to the definition of a tensor.
Examples of tensors are linear maps  and
and 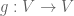 , and bilinear maps
, and bilinear maps  . They are tensors because they are multi-linear maps between vector spaces. Choices of basis vectors do not enter the picture until one wishes to describe a particular map to a friend; unless it is possible to define in terms of known linear maps such as
. They are tensors because they are multi-linear maps between vector spaces. Choices of basis vectors do not enter the picture until one wishes to describe a particular map to a friend; unless it is possible to define in terms of known linear maps such as  , it becomes necessary to write down a set of basis vectors and specify the tensor as an array of numbers with respect to this choice of basis vectors. This leads to the traditional definition of tensors, which is still commonly used in physics and engineering.
, it becomes necessary to write down a set of basis vectors and specify the tensor as an array of numbers with respect to this choice of basis vectors. This leads to the traditional definition of tensors, which is still commonly used in physics and engineering.
For convenience and consistency of notation, usually tensors are re-written as multi-linear maps into (or whatever the ground field is). Both and 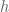 above are already of this form, but
above are already of this form, but  is not. This is easily rectified; there is a natural equivalence between linear maps and bilinear maps
is not. This is easily rectified; there is a natural equivalence between linear maps and bilinear maps 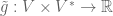 where
where 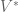 is the dual space of ; recall that elements of are simply linear functionals on , that is, if
is the dual space of ; recall that elements of are simply linear functionals on , that is, if 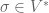 then
then 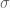 is a linear function
is a linear function 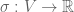 . This equivalence becomes apparent by observing that if, for a fixed
. This equivalence becomes apparent by observing that if, for a fixed 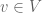 , the values of
, the values of  are known for every then the value of
are known for every then the value of 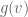 is readily deduced, and furthermore, the map taking a and a to
is readily deduced, and furthermore, the map taking a and a to  is bilinear; precisely, the correspondence between and
is bilinear; precisely, the correspondence between and  is given by
is given by  . (If that’s not immediately clear, an intermediate step is the realisation that if the value of
. (If that’s not immediately clear, an intermediate step is the realisation that if the value of 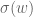 is known for every then the value of
is known for every then the value of 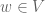 is readily determined. Therefore, if we are unhappy about the range of being , we can simply use elements of to probe the value of
is readily determined. Therefore, if we are unhappy about the range of being , we can simply use elements of to probe the value of 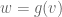 .)
.)
An equivalent definition of a tensor is therefore a multi-linear map of the form  ; see the wikipedia for details. (Linear maps between different vector spaces is a slightly more general concept and is not considered here for simplicity.)
; see the wikipedia for details. (Linear maps between different vector spaces is a slightly more general concept and is not considered here for simplicity.)
It remains to introduce the tensor product (and to give another definition of tensors, this time in terms of tensor products).
First observe that 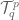 , the set of all multi-linear maps
, the set of all multi-linear maps 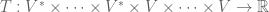 where there are
where there are 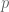 copies of and
copies of and 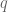 copies of , can be made into a vector space in an obvious way; just use pointwise addition and scalar multiplication of the multi-linear maps. Next, observe that
copies of , can be made into a vector space in an obvious way; just use pointwise addition and scalar multiplication of the multi-linear maps. Next, observe that  and are isomorphic. Furthermore, since
and are isomorphic. Furthermore, since  , the dual of the dual of , is naturally isomorphic to , it is readily seen that
, the dual of the dual of , is naturally isomorphic to , it is readily seen that  is isomorphic to . Can be constructed from multiple copies of and ?
is isomorphic to . Can be constructed from multiple copies of and ?
It turns out that is isomorphic to 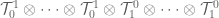 where there are copies of , copies of and
where there are copies of , copies of and 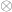 is the tensor product defined in The Tensor Product. Alternatively, one could have invented the tensor product by examining how
is the tensor product defined in The Tensor Product. Alternatively, one could have invented the tensor product by examining how 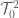 can be constructed from two copies of , then observing that the same construction can be repeated and applied to , thereby ‘deriving’ a useful operation denoted by .
can be constructed from two copies of , then observing that the same construction can be repeated and applied to , thereby ‘deriving’ a useful operation denoted by .
Another equivalent definition of a tensor is therefore an element of a vector space of the form  , and this too is explained in the wikipedia.
, and this too is explained in the wikipedia.
To summarise the discussion so far (and restricting attention to the scalar field for simplicity):
- Matrices do not, on their own, define linear maps between vector spaces (although they do define linear maps between Euclidean spaces ).
- A tensor is a multi-linear map whose domain and range involve zero or more copies of a vector space and its dual .
- Any such map can be re-arranged to be of the form .
- The space of such maps (for a fixed number of copies of and copies of ) forms a vector space denoted .
- It turns out that there exists a single operation which takes two vector spaces and returns a third, such that, for any
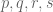 ,
,  is isomorphic to
is isomorphic to 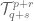 . This operation is called the tensor product.
. This operation is called the tensor product.
- Since and are isomorphic to and respectively, an equivalent definition of a tensor is an element of the vector space .
Some loose ends are now tidied up. Without additional reading though, certain remaining parts of this article are unlikely to be self-explanatory; the main purpose is to alert the reader what to look out for when learning from textbooks. First, it will be explained how an element of 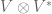 represents a linear map
represents a linear map 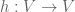 . Then an additional usage will be given of the tensor product symbol: the tensor product of two multi-linear maps results in a new multi-linear map. This additional aspect of tensor products was essentially ignored in The Tensor Product. Lastly, an explanation is given of why I omitted any mention of tensors in The Tensor Product.
. Then an additional usage will be given of the tensor product symbol: the tensor product of two multi-linear maps results in a new multi-linear map. This additional aspect of tensor products was essentially ignored in The Tensor Product. Lastly, an explanation is given of why I omitted any mention of tensors in The Tensor Product.
Let 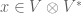 . The naive way to proceed is as follows. Introduce a basis
. The naive way to proceed is as follows. Introduce a basis 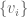 for and
for and 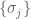 for ; different choices will ultimately lead to the same result. Then
for ; different choices will ultimately lead to the same result. Then  can be written as a linear combination
can be written as a linear combination 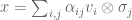 where the
where the 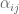 are scalars. Recall from The Tensor Product that the
are scalars. Recall from The Tensor Product that the  are just formal symbols used to distinguish one basis vector of from another. Here’s the trick; we now associate to each the linear map
are just formal symbols used to distinguish one basis vector of from another. Here’s the trick; we now associate to each the linear map  that sends to
that sends to 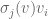 ; clearly
; clearly 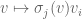 is a linear map from to . (This is relatively easy to remember, for how else could we combine
is a linear map from to . (This is relatively easy to remember, for how else could we combine  with
with 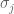 to obtain a linear map from to ?) Then, we associate to the linear map
to obtain a linear map from to ?) Then, we associate to the linear map 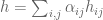 . It can be verified that this mapping is an isomorphism from the vector space to the vector space of linear maps from to , and moreover, the same mapping results regardless of the original choice of basis vectors for and . While this is useful for actual computations, it does not explain how we knew to use the above trick of sending to .
. It can be verified that this mapping is an isomorphism from the vector space to the vector space of linear maps from to , and moreover, the same mapping results regardless of the original choice of basis vectors for and . While this is useful for actual computations, it does not explain how we knew to use the above trick of sending to .
A more sophisticated way to proceed uses the universal property characterisation of tensor product and makes it clear why the above construction works. (The universal property characterisation is defined in the wikipedia among other places.) Essentially, under this characterisation, every bilinear map from 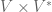 to induces a unique linear map from to , and conversely, every linear map from to induces a unique bilinear map from to . Now, we already know from earlier that linear maps from to are equivalent to bilinear maps from to . As now shown, choosing an element of is equivalent to choosing a linear map from to . Indeed, by definition of dual, linear maps from to are precisely the elements of
to induces a unique linear map from to , and conversely, every linear map from to induces a unique bilinear map from to . Now, we already know from earlier that linear maps from to are equivalent to bilinear maps from to . As now shown, choosing an element of is equivalent to choosing a linear map from to . Indeed, by definition of dual, linear maps from to are precisely the elements of  , as required.
, as required.
So far, we have only introduced the tensor product of two vector spaces. However, there is a companion operation which takes elements and 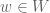 of vector spaces and returns an element
of vector spaces and returns an element 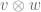 of the vector space
of the vector space  . (Recall that we have only introduced the formal symbol
. (Recall that we have only introduced the formal symbol  to denote a basis vector in the case where and
to denote a basis vector in the case where and 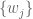 are chosen bases for and ; no meaning has been given yet to .) For calculations, it suffices to think of as the element obtained by applying formal algebraic laws such as
are chosen bases for and ; no meaning has been given yet to .) For calculations, it suffices to think of as the element obtained by applying formal algebraic laws such as  . Precisely, if
. Precisely, if  and
and 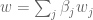 where and are chosen bases for and then is defined to be
where and are chosen bases for and then is defined to be  , as suggested by the formal manipulations
, as suggested by the formal manipulations 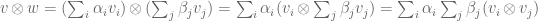 . I mention this only because I want to point out that this leads to the following simple rule for computing the tensor product of two multi-linear maps.
. I mention this only because I want to point out that this leads to the following simple rule for computing the tensor product of two multi-linear maps.
Let  and
and 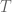 be multi-linear maps; in fact, for ease of presentation, only the special case
be multi-linear maps; in fact, for ease of presentation, only the special case 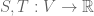 will be considered. Then a multi-linear map can be formed from and , namely,
will be considered. Then a multi-linear map can be formed from and , namely,  . This multi-linear map is denoted
. This multi-linear map is denoted 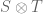 and is called the tensor product of and , in agreement with the discussion in the previous paragraph.
and is called the tensor product of and , in agreement with the discussion in the previous paragraph.
It is easier to motivate the tensor product of two tensors than it is to motivate the tensor product of two tensor spaces . Here is an example of such motivation.
What useful multi-linear maps can be formed from the linear maps ? Playing around, it seems  is a linear map; let’s call it
is a linear map; let’s call it  . Multiplication does not work because
. Multiplication does not work because  is not linear, so
is not linear, so  is not a tensor. The ordinary cross-product would lead to a map
is not a tensor. The ordinary cross-product would lead to a map 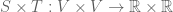 which is not of the form of a tensor as stated earlier. What we can do though is form the map
which is not of the form of a tensor as stated earlier. What we can do though is form the map  . We denote this bilinear map by
. We denote this bilinear map by 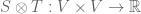 . Experience has shown the construction to be useful (which, at the end of the day, is the main justification for introducing new definitions and symbols), although for the moment, the choice of symbol has not been justified save for it should be different from more common symbols such as , and
. Experience has shown the construction to be useful (which, at the end of the day, is the main justification for introducing new definitions and symbols), although for the moment, the choice of symbol has not been justified save for it should be different from more common symbols such as , and  which mean different things, as observed immediately above. Furthermore, the definition of as stated above readily extends to general tensors…
which mean different things, as observed immediately above. Furthermore, the definition of as stated above readily extends to general tensors…
One could perhaps use the above paragraph as the start of an introduction to tensor products. In The Tensor Product, I chose instead to ignore tensors completely because, although there is nothing ‘difficult’ about them, the above indicates that there are a multitude of small issues that need to be explained, and at the end of the day, it is not even clear at the outset if there is any use in studying tensor products of tensor spaces! What does the fancy symbol buy us that we could not have obtained for free just by working directly with multi-linear maps and arrays of numbers? (There are benefits, but they appear in more advanced areas of mathematics and hence are hard to motivate concretely at an elementary level. Of course, one could say the tensor product reduces the study of multi-linear maps to linear maps, that is, back to more familiar territory, but multi-linear maps are not that difficult to work with directly in the first place. )
The Tensor Product motivated the tensor product by wishing to construct ![\mathbb{R}[x,y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%2Cy%5D&bg=ffffff&fg=555555&s=0&c=20201002) from
from ![\mathbb{R}[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D&bg=ffffff&fg=555555&s=0&c=20201002) and
and ![\mathbb{R}[y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5By%5D&bg=ffffff&fg=555555&s=0&c=20201002) . It was stated there that this allowed properties of to be deduced from properties of . A solid example of this would be localisation of rings: if we have managed to show that the localisation
. It was stated there that this allowed properties of to be deduced from properties of . A solid example of this would be localisation of rings: if we have managed to show that the localisation ![(\mathbb{R}[x])[1/x]](https://s0.wp.com/latex.php?latex=%28%5Cmathbb%7BR%7D%5Bx%5D%29%5B1%2Fx%5D&bg=ffffff&fg=555555&s=0&c=20201002) is isomorphic to the ring of Laurent polynomials in one variable, then properties of the tensor product allow us to conclude that the localisation
is isomorphic to the ring of Laurent polynomials in one variable, then properties of the tensor product allow us to conclude that the localisation ![(\mathbb{R}[x,y])[1/xy]](https://s0.wp.com/latex.php?latex=%28%5Cmathbb%7BR%7D%5Bx%2Cy%5D%29%5B1%2Fxy%5D&bg=ffffff&fg=555555&s=0&c=20201002) is isomorphic to the ring of Laurent polynomials in two variables. Even without such examples though, I am more comfortable taking for granted that it is useful to be able to construct from and than it is useful to be able to construct
is isomorphic to the ring of Laurent polynomials in two variables. Even without such examples though, I am more comfortable taking for granted that it is useful to be able to construct from and than it is useful to be able to construct  from
from 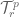 and
and 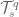 .
.
