Archive
Tensor Products Introduced as Most General Multiplication (and as Lazy Evaluation)
This note is a fresh attempt at introducing tensor products in a simple and intuitive way. The setting is a vector space 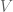



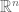
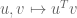
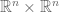
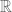
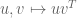
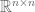



Let 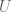

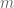
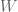




What does it mean for 

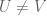



Not knowing 
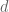
While the tensor product 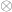

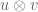
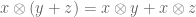
The first point is that we can treat
Whereas there are many metrics “incompatible” with each other, the rules for multiplication are sufficiently rigid that there exists a “most general multiplication”, and all other multiplications are special cases of it, as explained presently. The tensor product
To consider a specific case first, take 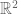


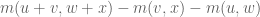


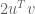

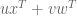

Readers wishing to think further about the above example are encouraged to consider that the most general multiplication returning a real-valued number is of the form 


The general situation works as follows. Given vector spaces 
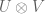
At this point, I leave the reader to look up elsewhere the definition of a tensor product and relate it with the above.
Simple Derivation of Neyman-Pearson Lemma for Hypothesis Testing
This short note presents a very simple and intuitive derivation that explains why the likelihood ratio is used for hypothesis testing.
Recall the standard setup: observed is a realisation 

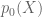

The observation space is to be partitioned into two regions, one region labelled zero and the other unity. If 




Since there is a trade-off between being correct when
Mathematically, the region 


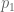
The trick is to imaging the observation space as broken up into many small tiles fitting together to cover the observation space. (If the observation space is drawn as a square then imagine dividing it into hundreds of small squares.) With this quantisation, finding the region
Think of starting with 


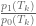
As the size of the tiles shrinks to zero, the “limit” is the likelihood ratio 



The above is a hand-waving argument and is not the best on which to base a rigorous proof. Often this is the case though: an intuitive derivation is subsequently verified by a less intuitive but more elementary mathematical argument. An elementary proof can be found in the Wikipedia.
Understanding (real- and complex-valued) Inner Products
This short note addresses two issues.
- How can we intuitively understand a complex-valued inner product?
- If an inner product structure is given to a vector space, how can we understand the resulting geometry?
Since inner products are associated with angles, and since we can understand angles, there is temptation to interpret inner products in terms of angles. I advocate against this being the primary means of interpreting inner products.
An inner product 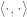

What then is the purpose of the inner product? Not all norms have the same properties. Under some norms, projection onto a closed subspace may not be unique, for example. When interested in shortest-norm optimisation problems, the most desirable situation to be in is for the square of the norm to be quadratic, since then differentiating it produces a linear equation. In infinite dimensions, what does it mean for the square of a norm to be quadratic?
The presence of an inner product structure means the square of the norm is quadratic. Furthermore, the inner product “decomposes” the norm in a way that gives direct access to the derivative of the norm squared.
The remaining issue is how to understand complex-valued inner products. Given the above, the natural starting place is to consider endowing a complex vector space with a norm. Keeping the axioms of a real-valued normed vector space seems sensible; it implies that scaling a vector by 
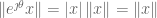
Then one asks what it means for the square of a norm to be quadratic. From the real-valued case, one guesses that one wants to be able to represent the square of the norm as a bilinear form: 



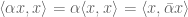

By treating the norm as the primary structure, one does not have to worry about giving an intuitive meaning to the inner product of two vectors not being a purely real-valued number; the inner product is there merely to expose the square of the norm as being quadratic. A complex-valued inner product is recoverable from its norm and hence no geometric information is lost. (Of course, orthogonality remains an important concept.) If one really wanted, one could play around with examples in 


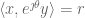
Are Humans Smart and Computers Dumb? Can Computers Become Better at Helping Humans Solve Challenging Problems?
Computers are generally seen as “dumb”, unable to think for themselves and therefore unable to solve certain complex tasks that humans, being “smart”, are able to solve relatively easily. Humans outperform computers at speech recognition, many image processing problems, and at real-time control problems such as walking – bipedal robots cannot manoeuvre as well as humans. Some may argue computers will never be able to prove mathematical theorems or engineer complex systems as well as mathematicians or engineers.
From a pragmatic perspective, “being smart” is ill-defined. Roughly speaking, a solution is “smart” if a formulaic solution is not known (or if the solution is obtained much more efficiently than via a formulaic but brute force solution, e.g. one could argue humans are still “smarter” at chess than computers, even though computers can now beat humans).
My current viewpoint is that:-
- we are probably not as smart as we may think;
- computers are dumb primarily because we only know how to program them that way;
- regardless, the future vision should be of challenging problems being solved jointly by humans and computers without the current clunky divide between what humans do and what computers do. We should be aiming for semi-automated design, not fully-automated design.
The following three sections elaborate on the above three points in turn. First a summary though.
Summary: We should not dismiss the idea that computers can help us in significantly better ways to solve challenging problems simply because we see a divide: we are smart and computers are not. Ultimately, smartness probably can be recreated algorithmically provided computers (robots?) and humans start to interact extensively. But well prior to this, computers can become better at assisting us solve challenging problems if we start to understand how much ‘intuition’ and ‘problem solving’ boils down to rules and pattern recognition. Certainly not all intuition would be easy to capture, but often challenging problems involve large amounts of fairly routine manipulations interspersed by ingenuity. Semi-automated design aims to have a human and a computer work together, with the computer handling the more routine manipulations and the human providing high-level guidance which is where the ingenuity comes in.
Readers short of time but interested primarily in a suggested research direction can jump immediately to the last section.
As the focus is on solving mathematical and engineering problems, no explicit consideration is given to philosophical or spiritual considerations. Smartness refers merely to the ability to solve challenging (but not completely unconstrained) problems in mathematics and engineering.
How Smart Are Humans?
A definitive answer is hard to come by, but the following considerations are relevant.
Human evolution traces back to prokaryote cells. At what point did we become “smart”? My favoured hypothesis is that as the brain got more complex and we learnt to supplement our abilities with tools (e.g. by writing things down to compensate for fallible memory), exponential improvement resulted in our capabilities. (I vaguely recall that one theory of how our brain got more complex was by learning to use tools that lead to improved diets, e.g. by breaking bones and accessing the marrow.) It seems much less likely we suddenly picked up an “intelligence gene” that no other creature has. Flies, rats, apes and humans are not that different in terms of basic building blocks.
When comparing humans to computers, one should not forget that humans require 21 or so years of boot-up time. And different humans have different strengths; not all are equally good at solving mathematical problems or engineering systems. An unpleasant a thought as it may be, consider an extraterrestrial who has a choice of building and programming computers or breeding and teaching humans. Which would be a better choice for the extraterrestrial wishing for help in solving problems? (Depending on the initial gene pool and initial population size, it might take 100 years before a human is bred that is good at a particular type of problem. Regardless, if starting from scratch, there is an unavoidable 15-20 year delay.)
Then there is the issue of what precisely smartness is. Smartness is defined by a social phenomenon. At a small scale, one just has to look at review committees and promotion panels to realise there is not always agreement on what is smart and what is not. More striking though, smartness is relative – humans compare with each other and with the world around them. There are infinitely more problems we cannot solve than we can solve, yet no one seems to conclude that we are therefore not smart. We look at what we can do and compare that with what others can do. In a similar vein, a computer can effortlessly produce millions and millions of theorems and proofs in that it could systematically piece axioms together to form true sentences, recording each new sentence as a “theorem” and the trail leading to it as a “proof”. Yet this would be dismissed immediately as not useful. So ‘usefulness to humans’ plays a role in defining smartness.
How do humans solve problems? Following again the principle of Occam’s Razor, the simplest hypothesis that comes to my mind involves the following factors. Most of our abilities come from having to compete in the world (think back thousands of years). Image processing is crucial, and as over half the brain is involved to some extent with vision, a large part of how we reason is visual. (Even if we do not explicitly form images in our minds, our subconscious is likely to be using similar circuitry.) We also need to be able to understand cause and effect — if I stand next to that lion, I will get eaten — which leads to the concept of thinking systematically. So my current hypothesis is that systematic thinking (including understanding cause and effect) and pattern recognition are the main players when it comes to reasoning. The mathematics and engineering we have developed, largely fits into this mould. Rigorous systemisation and writing down and sharing of results have lead to ‘amazing’ results that no single human could achieve (insufficient time!) but at each little step, ideas come from experience and nowhere else. Those that can calculate faster, are more perceptive, are more inquisitive, tend to find the “right” types of patterns, have greater focus and stamina, and are more attuned to what others may find interesting, have significant competitive advantages, but to rule a line and say computers can never do mathematics or engineering is unjustified. (The issue of creativity will be discussed in the next section.)
A final point before moving on. Speech recognition is very challenging for computers. Yet are we smart because we can understand speech? Speech was something created over time by humans for humans. Presumably grunts turned into a small vocabulary of words which grew into phrases and more complicated structures. The point though is that at no time could the process evolve to produce something humans couldn’t understand, because by definition, the aim was to communicate, and if communication was not working, another approach would be taken. If we could learn the languages of all extraterrestrials, perhaps we really are smart, but I’m skeptical.
How can Computers be Made Smarter?
The three main characteristics of a computer system (i.e., something built to do speech recognition or solve mathematical problems) are its size (raw processing power), architecture (e.g., what parts can communicate with what other parts) and the software running on it.
Since humans tend to set the benchmark at what humans can do, a minimum amount of raw processing power is required before a computer can even hope to do something “smart”. Yet the architecture is even more important. Engineers currently do not build computers anything like the way nature builds brains. It is very likely that current computational architectures are ineffective for the types of pattern recognition the human brain engages in.
More interestingly, the architecture of the human brain evolves over time. In simple terms, it learns by changing its architecture. There are two obvious components; via DNA, natural selection increases the chances that a human is born with a ‘good’ architecture to start with. Then there is the long process of refining this architecture through everyday experiences and targeted learning (e.g., attending school).
There is nothing stopping us from building reconfigurable computers that are massively interconnected, thereby very crudely approximating the architecture of a brain. (I suspect this may involve a shift away from ‘reliable’ logic gates to logic gates (or equivalent) that work some but not all of the time, for there is a trade-off between density and reliability.)
With remarkable advances in technology, the real challenge looking forwards is the software side. Because we don’t understand precisely the sort of pattern recognition the brain uses to solve problems, and because until recently the technology was not there to build massively interconnected reconfigurable computers, no one has seriously tried to make a computer “smart” in the way I have been referring to in this essay. (This is not overlooking Artificial Intelligence whose approach was partly hampered by the available technology of the day, and which I suspect never delved deeper and deeper into how the brain does pattern recognition — once artificial neural networks came on the scene, there were sufficiently many research questions for AI researchers to chase that they did not continuously return to the biology to understand better and better how the brain does pattern recognition. And in fairness, as they lacked the computational power for hypothesis testing, it would most likely have been a futile endeavour anyway.)
Summarising this section, several points can be made. Current computing systems (which nevertheless serve the majority of their intended purposes extremely well) seem to be a ‘mismatch’ for doing what humans are good at doing, therefore, they come across as “dumb”. There is no evidence yet to suggest there is a barrier to building (this century) a computing system that is “smart” in some respects, but it will require a whole new approach to computing. It is not clear whether imitating the architecture of the human brain is the best thing to do, or if there is an even more efficient approach waiting to be discovered. Nevertheless, if smartness is being measured against what humans can do, a good starting point is starting with similar resources to what a human has.
Bringing in points from the preceding section, one must not forget though that humans have been ‘trained’ over centuries (natural selection), that each individual then takes an additional 21 years of training, during which time they are communicating with and learning from other individuals, and even then, we tend to work on the problems we believe we can solve and ignore the rest. This suggests we have a narrow definition of “smartness” and perhaps the only real way for a computer to be “smart” in our eyes is if it were to ‘grow up’ with humans and ‘learn’ (through daily feedback over 21 years) what humans value.
Indeed, smartness is usually linked with creativity and being able to solve “completely new” problems. (I would argue though that the problems we can solve are, by definition, not as distant from other problems we have solved before as we would like to think. Who knows how much the subconscious remembers that our conscious mind does not.) Creativity, even more than smartness, is linked to how humans perceive themselves relative to others. A random number generator is not creative. An abstract artist is. Some computer generated pictures coming from fractals or other mathematical constructs can be aesthetically pleasing to look at but is creativity involved once one realises a formulaic pattern is being followed? When it comes to problem solving, creativity and smartness come back largely to usefulness, or more generally, to some notion of value. We solve problems by instinctively knowing which of the thousands of possible approaches are most likely not to work, thereby leaving a manageable few options to work our way through. When we “create” a new theorem or engineer a new system, we are credited with creativity if it is both potentially useful (“sensible”?) and different from what has been done before. A random number generator succeeds at being different; the challenge is teaching a computer a sense of value; I suspect this is achievable by having computers interact with humans as described above (it is all just pattern recognition refined by external feedback!), and perhaps humans can even learn to write down systematically not just an algebraic proof of a mathematical result but also the “intuition” behind the proof, thereby enabling computers to learn like humans by studying how others solve problems.
A Future Vision of Semi-automated Design
Although arguing that if we wanted computers to be smart then we are most likely going to be able to achieve that goal eventually, the more important question is whether we should be trying to head directly there. Personally, a more useful and more easily achievable goal is to work towards semi-automation and not full automation. At the moment there is essentially no way to guide a computer towards a goal; we run something, we wait, we get a result. Often we make a modification and try again. But we are not really interacting with the computer, just using it to shorten the time it takes for us to calculate something. By comparison, two people can work together on a design problem or a mathematical proof; there are periods when they work alone, but there are periods when they come together to discuss and get ideas from each other before going off to think on their own again. Semi-automation lies somewhere between these two extremes: the computer need not be “smart” like a human, but it should come across as being more than just a dumb calculator (even if, at the end of the day, all it is doing are calculations!).
Efficient exchange of information is vital. Computers can store more data than a brain can, but we can probe someone else’s brain for information much more efficiently than we can probe a computer’s memory banks. Largely this is because exchange of information is more efficient when there is shared knowledge that need not be explicitly transmitted.
Semi-automated Theorem Proving
There are so many mistakes, both big and small, in the published literature (even the top journals) that it seems not only highly desirable but inevitable we will ultimately have all mathematical works stored on and verified by computers. This is certainly not a new dream, so how far are we from achieving it?
Although proof verification systems exist, otherwise simple proofs become excessively long when translated into a suitable form for the computer to check. Exchange of information is far from efficient! At the other extreme, automated theorem provers exist, but are yet to prove any theorems of substance. I propose the following stages of research.
1) Choose an area (e.g. basic set theory, or basic set theory and finite-dimensional linear algebra). Work towards devising a notation so that humans can enter a theorem and proof using a similar amount of effort to typing up the theorem and proof for a formal set of lecture notes. To improve efficiency, the notation does not need to be unambiguous since the computer can always ask for clarification if it cannot figure out the correct meaning. Similarly, the gaps between each step of the proof may not always be sufficiently small for the computer to be able to fill in, nevertheless, the computer should have a go, and ask for help (e.g., ask for a sub-step to be inserted) if it fails.
2) Enhance stage one above by having the computer give a list of suggestions whenever it gets stuck; it is easier for the user to click on the correct suggestion than to type in the answer, and if none of the suggestions are correct, the user can always fall back to entering the answer. Here, some method of ranking the suggestions is required (for otherwise there might be too many suggestions). Initially, this can be based on the computer determining “what we already know” and “what we want to find out”, then searching through the axioms and existing theorems to find something that relates either to “what we already know” (a possible ‘starting move’) or “what we want to find out” (a possible ending move).
3) Stage two will eventually prove inefficient as the number of theorems grows and the proofs become more complicated. Some sort of ‘learning’ and ‘intuition’ on behalf of the computer is unavoidable if humans and computers are to interact significantly more efficiently. Perhaps ultimately pattern recognition, as discussed in previous sections, becomes unavoidable, but one should not be too hasty in ruling out the possibility that a fair amount of intuition is more formulaic than we think. Stage three then is supplementing theorems and proofs with basic intuition. The first example that comes to mind is working with bounds, e.g., the triangle inequality. A computer can be taught that if it wants to prove x and y are close, then it can do this if it can find a point z that is close to x and also close to y. Or in another form (i.e., 
Certainly some proofs require deep intuition and ingenuity, but even then, a large part of the proof is generally fairly routine. Once a human has specified the “stepping stones”, the routine parts can be filled in (semi-)automatically by the computer working its way through its collection of routine moves and supplemented by basic intuition to rank the order in which it should try the moves.
Stages 1 to 3 are within our grasp and would already have a tremendous impact if they work as expected.
4) Stages 1 to 3 were concerned with a user stating a theorem and sketching a proof, with the aim that the computer can fill in the missing steps of the proof and thereby verify the correctness of the theorem, falling back to asking for more information if it gets stuck. Stage 4 is for the computer to work with a user in proving or disproving a theorem. That is, the user states a conjecture, then through a series of interactions with the computer, the user either finds a proof or a counterexample in a shorter time than if the user were to proceed unassisted. Refinement of the “intuition engine” may or may not be necessary. Some way for the user to suggest efficiently (minimum of keystrokes) to the computer what to try next is required. Some way for the computer to make suggestions to the user as to what to (and what not to) try next is required. [I omit my ideas for how to do this because they will most likely be superseded by the insight gained by anyone working through stages 1 to 3.]
5) The fifth stage is for computers to propose theorems of their own. In the first instance, they can look for repeated patterns used in proofs stored in its database. The examples that come to mind immediately are category theory and reproducing kernel Hilbert spaces. In part, these areas came into existence because mathematicians observed the same types of manipulations being carried out in different situations, identified the common threads and packaged them up into their own theory or “toolbox”.
Semi-automated Chip Design
Engineers have long had the dream of being able to specify what they would like a software program or an electronic circuit to do, push a button, and have a computer generate the software or the circuit. Even more significant than saving time, if done properly, this would ensure the software (and possibly the circuit, although this is a bit harder to guarantee in more complicated situations when extra considerations such as EM interactions must be taken into account) is guaranteed to work correctly. There is a staggering amount of buggy software and hardware out there that this dream is becoming more and more desirable to achieve.
Basically, all the ideas discussed earlier are relevant here. Instead of a library of mathematical theorems, proofs and accompanying intuition being built up, a library of software or a library of electronic circuits is built up. Humans will always be part of the design loop, but more and more of the routine work can be carried out by a computer. Brute force algorithms and heuristics must be replaced by a way of encoding “intuition” and “lessons from past experience”, thereby allowing humans and computers to interact much more efficiently.
